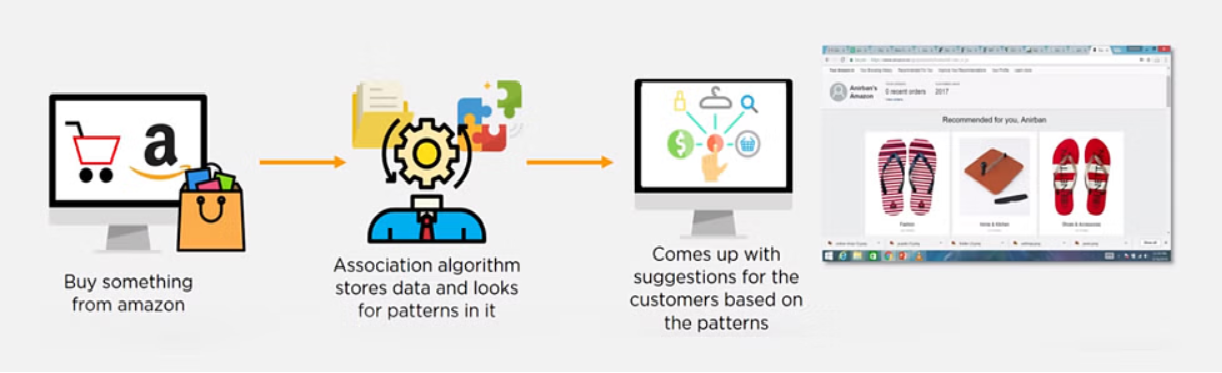
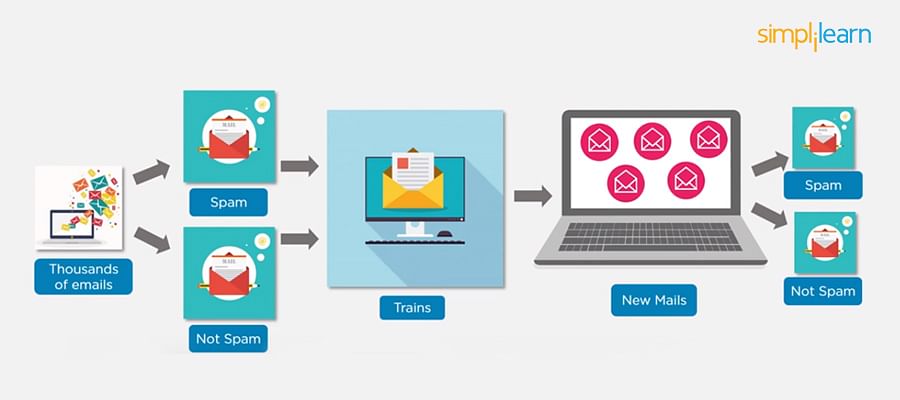
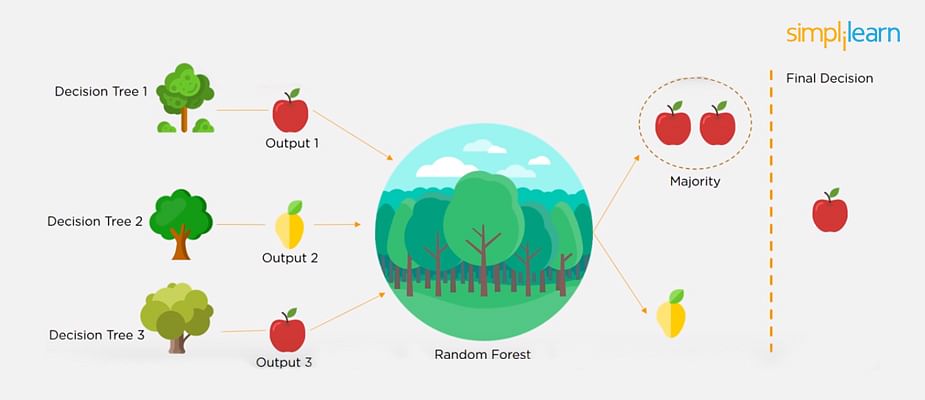
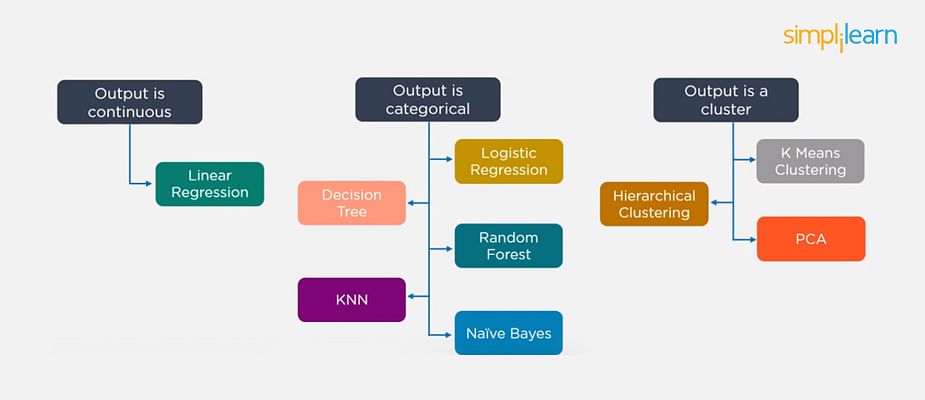
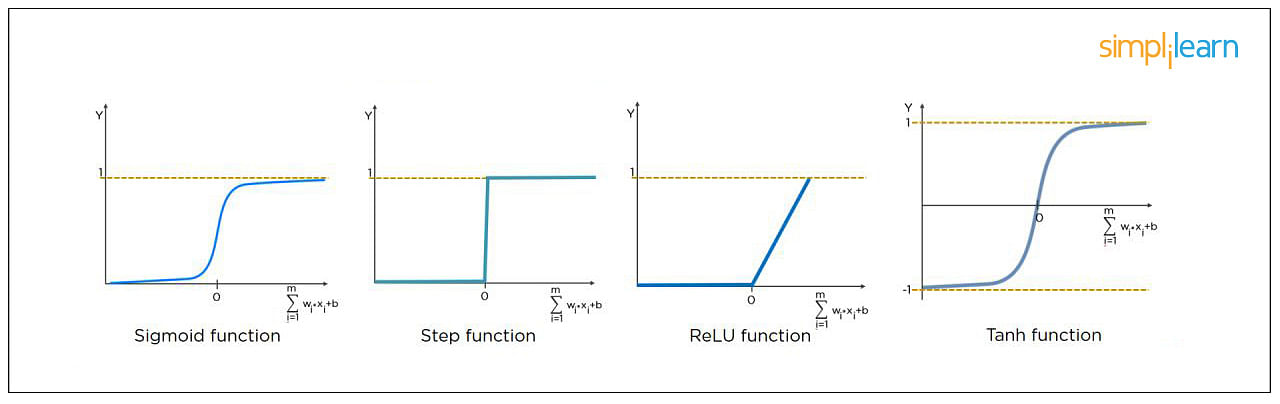
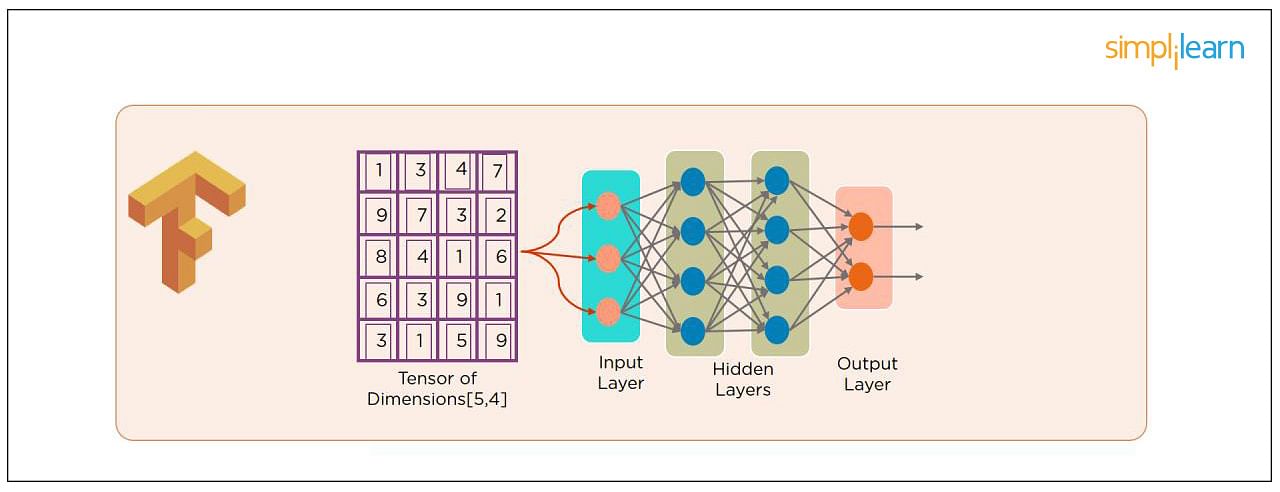
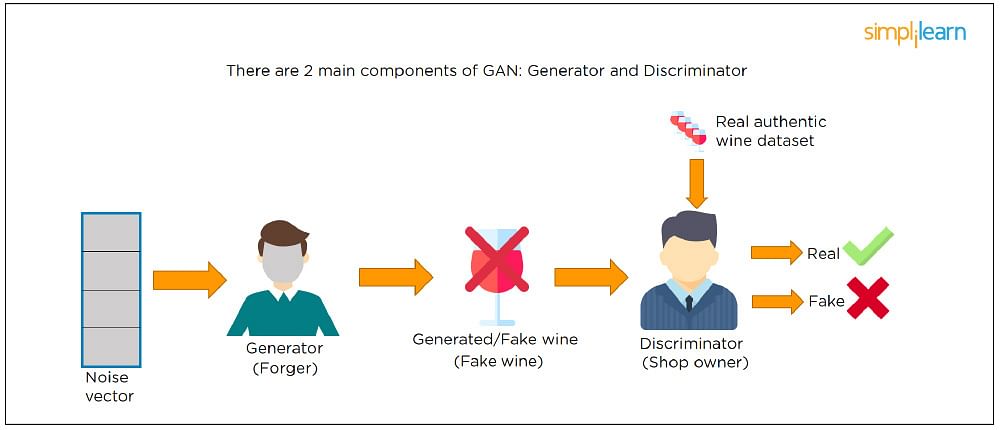
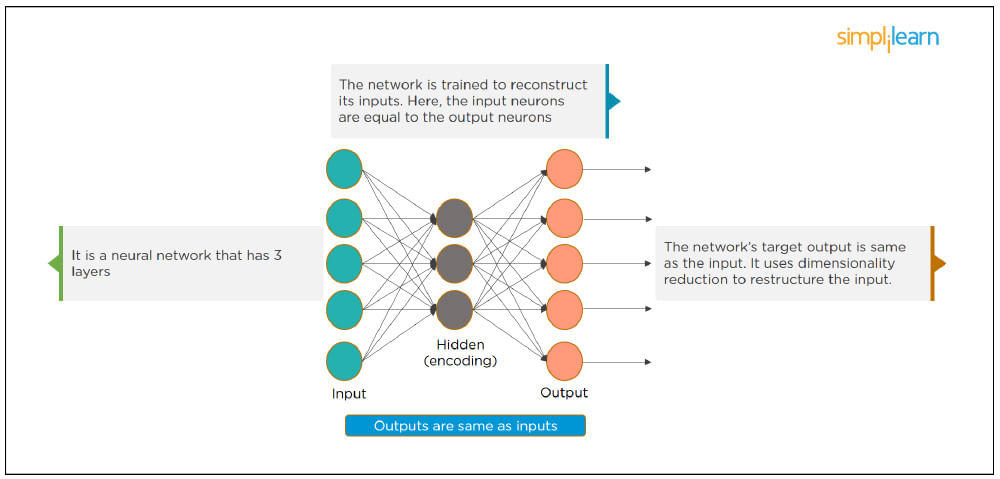
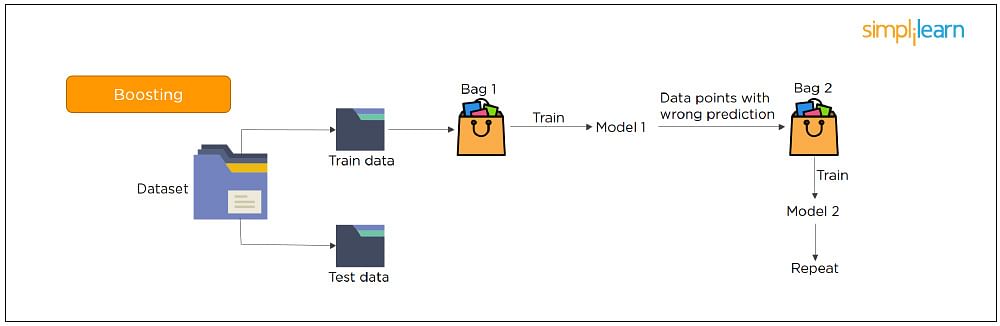
Python
1. What exactly are pandas?
Pandas is a Python package that provides a large number of data structures for data-driven activities. Pandas fit in any function of data operation, whether it’s academics or tackling complicated corporate challenges, thanks to their interesting characteristics. Pandas is one of the most important programs to master because it can handle a wide range of files.
2. What are data frames, exactly?
A changeable data structure in pandas is called a data frame. Pandas can handle data that is organized on two axes and is heterogeneous. (Columns and rows)
Using pandas to read files:
– \s1 Import pandas using the PD df=p command. read CSV(“mydata.csv”)
df is a pandas data frame in this case. In pandas, read CSV() is used to read a comma-separated file as a data frame.
3. What is a Pandas Series, and what does it entail?
A series is a one-dimensional data structure in Pandas that may hold data of nearly any type. It has the appearance of an excel column. It is used for single-dimensional data manipulations and supports multiple operations.
4. What does it mean when pandas form a group?
A pandas groupby is a feature that allows you to separate and group objects using pandas. It is used to group data by classes, entities, which could then be used for aggregation, similar to SQL/MySQL/oracle group by. One or more columns can be used to group a data frame.
5. How do I make a data frame out of a list?
To make a data frame from a list,
1) start by making an empty data frame.
2)Add lists to the list as individual columns.
6. What is the best way to make a data frame from a dictionary?
To generate a data frame, a dictionary can be explicitly supplied as an input to the DataFrame() function.
7. In Pandas, how do you mix data frames?
The concat(), append(), and join() functions in pandas can stack two separate data frames horizontally or vertically.
Concat is a vertical stacking of data frames into a single data frame that works best when the data frames have the same columns and can be used for concatenation of data with comparable fields.
Append() is used to stack data frames horizontally. This is the finest concatenation function to use when merging two tables (data frames).
When we need to extract data from many data frames with one or more common columns, we utilize join. In this situation, the stacking is horizontal.
8. What types of joins can Panda provide?
A left join, an inner join, a right join, and an outside join are all present in Pandas.
9. In Pandas, how do you merge data frames?
The type and fields of the different data frames being merged determine how they are combined. If the data has identical fields, it is combined along axis 0, otherwise, it is merged along axis 1.
10. What is the best way to get the first five entries of a data frame?
We may get the top five entries of a data frame using the head(5) function. df.head() returns the top 5 rows by default. df.head(n) will be used to fetch the top n rows.
11. How can I get to a data frame’s last five entries?
We may get the top five entries of a data frame using the tail(5) method. df.tail() returns the top 5 rows by default. df.tail(n) will be used to fetch the last n rows.
12. What are comments, and how do you add them to a Python program?
A piece of text meant for information is referred to as a comment in Python. It’s especially important when multiple people are working on a set of codes. It can be used to inspect code, provide feedback, and troubleshoot it. There are two different categories of comments:
- Comment on a single line
- Comment with many lines
13. In Python, what is the difference between a list and a tuple?
Tuples are immutable, whereas lists are mutable.
14. In Python, what is a dictionary? Give a specific example.
A Python dictionary is a list of elements that are not in any particular order. Keys and values are written in curly brackets in Python dictionaries. The retrieval of value for known keys is optimized in dictionaries.
15. Find out the mean, median and standard deviation of this numpy array -> np.array([1,5,3,100,4,48])
import numpy as np n1=np.array([10,20,30,40,50,60]) print(np.mean(n1)) print(np.median(n1)) print(np.std(n1))
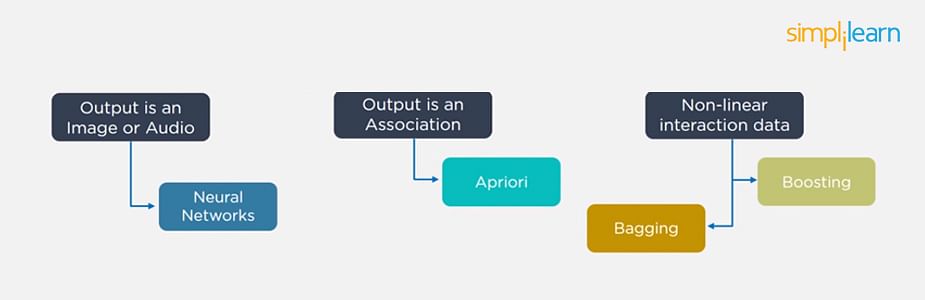
16. What is the definition of a classifier?
Any data point’s class is predicted using a classifier. Classifiers are hypotheses that are used to assign labels to data items based on their classification. To understand the relationship between input variables and the class, a classifier frequently needs training data. In Machine Learning, classification is a supervised learning strategy.
Any data point’s class is predicted using a classifier. Classifiers are hypotheses that are used to assign labels to data items based on their classification.
17. How do you change a string to lowercase in Python?
The method: can be used to convert all uppercase characters in a string to lowercase characters.
string.lower()
ex: string = ‘GREATLEARNING’ print(string.lower())
o/p: greatlearning
18. What’s the best way to get a list of all the keys in a dictionary?
We can get a list of keys in a variety of ways, including: dict.keys()
This method retrieves all of the dictionary’s accessible keys.
dict = {1:a, 2:b, 3:c} dict.keys()
o/p: [1, 2, 3]
19. How do you capitalize a string’s first letter?
To capitalize the initial character of a string, we can use the capitalize() method. If the initial character is already capitalized, the original string is returned.
Syntax: string_name.capitalize() ex: n = “greatlearning” print(n.capitalize())
o/p: Greatlearning
20. In Python, how do you insert an element at a specific index?
The insert() function is a built-in Python function. It’s possible to use it to insert an element at a specific index.
Syntax: list_name.insert(index, element)
ex: list = [ 0,1, 2, 3, 4, 5, 6, 7 ]
#insert 10 at 6th index
list.insert(6, 10)
o/p: [0,1,2,3,4,5,10,6,7]
21. How are you going to get rid of duplicate elements from a list?
To delete duplicate elements from a list, you can use a variety of techniques. The most typical method is to use the set() function to convert a list into a set, then use the list() function to convert it back to a list if necessary.
22. What exactly is recursion?
A recursive function is one that calls itself one or more times within its body. One of the most significant requirements for using a recursive function in a program is that it must end, otherwise, an infinite loop would occur.
23. Explain how to use Python’s List Comprehension feature.
List comprehensions are used to change one list into a different one. Elements can be included in the new list on a conditional basis, and each member can be modified as needed. It consists of a bracketed statement that precedes a for clause.
24. What is the purpose of the bytes() function?
A bytes object is returned by the bytes() function. It’s used to convert things to bytes objects or to produce empty bytes objects of a given size.
25. What are the various types of Python operators?
The following are the basic operators in Python:
Arithmetic ( +, -, Multiplication(*), Division(/), Modulus( percent ) ), Relational (, >, =, >=, ==,!=, ), Assignment ( =. +=, -=, /=, *=, percent = ), Logical ( =. +=, -=, /=, *=, percent = ), ( and, or not ), Bitwise Operators, Membership, and Identity
26. What exactly is a ‘with statement’?
In Python, the “with” statement is used to handle exceptions. Without utilizing the close() function, a file can be opened and closed while executing a block of code containing the “with” line. It basically makes the code a lot easier to read.
27. In Python, what is the map() function?
In Python, the map() method is used to apply a function to all components of an iterable. Function and iterable are the two parameters that make up this function. The function is supplied as an argument, and it is then applied to all elements of an iterable (which is passed as the second parameter). As a result, an object list is returned.
28. In Python, what is __init__?
In Python, the _init_ function, often known as the function Object() { [native code] } in OOP, is a reserved method. When a class is used to construct an object, the _init_ method is used to access the class attributes.
29. What tools are available to perform the static analysis?
Pychecker and Pylint are two static analysis tools for finding flaws in Python. Pychecker finds flaws in source code and issues warnings regarding the style and complexity of the code. Pylint, on the other hand, checks whether the module adheres to a coding standard.
30. What is the difference between tuple and dictionary?
A tuple differs from a dictionary in that a dictionary is mutable, whereas a tuple is not. In other words, a dictionary’s content can be modified without affecting its identity, but this is not allowed with a tuple.
Dictionary is one of Python’s built-in datatypes. It establishes a one-to-one correspondence between keys and values. Dictionary keys and values are stored in pairs in dictionaries. Keys are used to index dictionaries.
31. In Python, what is the meaning of pass?
Pass is a statement that has no effect when used. To put it another way, it’s a Null statement. The interpreter does not ignore this statement, but no action is taken as a result of it. It’s used when you don’t want any commands to run but yet need to make a statement.
The pass statement is used when there’s a syntactic but not an operational requirement. For example – The program below prints a string ignoring the spaces.
var=”Si mplilea rn”
for i in var:
if i==” “:
pass
else:
print(i,end=””)
Here, the pass statement refers to ‘no action required.’
32. In Python, how do you copy an object?
Although not all objects can be duplicated in Python, the majority of them can. To copy an object to a variable, we can use the “=” operator.
33. How do you turn a number into a string?
To convert a number to a string, use the built-in function str().
34. What are the differences between a module and a package in Python?
Modules are the building blocks of a program. A module is a Python software file that imports other characteristics and objects. A program’s folder is a collection of modules. Modules and subfolders can be found in a package.
35. In Python, what is the object() function?
The object() method in Python returns an empty object. This object can’t have any new attributes or methods added to it.
36. What do NumPy and SciPy have in common?
SciPy stands for Scientific Python, while NumPy stands for Numerical Python. NumPy is the basic library for defining arrays and solving elementary mathematical issues, whereas SciPy is used for more sophisticated problems like numerical integration, optimization, and machine learning.
37. What does len() do?
len() is used to determine the length of a string, a list, an array, and so on. ex: str = “greatlearning” print(len(str)) o/p: 13
38. What does encapsulation mean in Python?
Encapsulation refers to the joining of code and data. Consider a Python class.
39. In Python, what is the type ()?
type() is a built-in method that returns the object’s type or creates a new type object based on the inputs passed in.
40. What is the purpose of the split() function?
Split is a function that divides a string into shorter strings using defined separators.
The split() function splits a string into a number of strings based on a specific delimiter.
Syntax –
string.split(delimiter, max)
Where:
the delimiter is the character based on which the string is split. By default it is space.
max is the maximum number of splits
Example –
>>var=“Red,Blue,Green,Orange”
>>lst=var.split(“,”,2)
>>print(lst)
Output:
[‘Red’,’Blue’,’Green, Orange’]
Here, we have a variable var whose values are to be split with commas. Note that ‘2’ indicates that only the first two values will be split.
41. What are built-in types does python provide?
Python includes the following data types:
Numbers: Python distinguishes between three types of numbers:
- All positive and negative numbers without a fractional part are integers.
- Float: Any real number that may be represented in floating-point format.
- Complex numbers: x+yj represents a number with a real and imaginary component. x and y are floats, and j is -1 (often known as an imaginary number because of its square root).
Boolean: The Boolean data type is a data type that can only have one of two values: True or False. The letters ‘T’ and ‘F’ are capitalized.
A string value is made up of one or more characters enclosed in single, double, or triple quotations.
List: A list object is an ordered collection of one or more data objects in square brackets, which might be of different types. Individual elements in a list can be added, edited, or deleted since they are modifiable.
Set: Curly brackets encompass an unordered group of unique objects.
Frozen set: They’re similar to sets, but they’re immutable, meaning we can’t change their values after they’ve been created.
Dictionary: A dictionary is an unordered object in which each item has a key and we may retrieve each value using that key. Curly brackets surround a collection of similar pairs.
42. In Python, how do you reverse a string?
There are no built-in functions in Python to let us reverse a string. For this, we’ll need to use an array slicing operation.
>> #Input
>>df = pd.DataFrame(np.arange(25).reshape(5, -1))
>> #Solution
>>df.iloc[::-1, :]
43. How do I find out the Python version in CMD?
Press CMD + Space to see the Python version in CMD. This activates Spotlight. Type “terminal” into this box and hit Enter. Type python –version or python -V and press enter to run the program. The python version will be returned in the line following the command.
44. When it comes to identifiers, is Python case sensitive?
Yes. When it comes to identifiers, Python is case-sensitive. It’s a case-by-case language. As a result, variable and Variable are not synonymous.
45. How can I use values from existing columns to build a new column in Pandas?
On a pandas data frame, we can conduct column-based mathematical operations. Operators can be used on Pandas columns that contain numeric values.
46. What are the many functions that grouby in pandas can perform?
Multiple aggregate functions can be utilised with grouby() in pandas. sum(), mean(), count(), and standard are a few examples().
Data is separated into groups based on categories, and the data in these individual groups can then be aggregated using the functions listed above.
47. In Pandas, how do you choose columns and add them to a new data frame? What if two columns with the same name exist?
If df is a pandas data frame, df.columns return a list of all columns. We may then select columns to create new columns.
If two columns have the same name, both of them are copied to the new data frame.
48. How to delete a column or group of columns in pandas?
drop() function can be used to delete the columns from a data frame.
49. Given the following data frame drop rows having column values as A.
|
Col1 |
Col2 |
| 0 |
1 |
A |
| 1 |
2 |
B |
| 2 |
3 |
C |
Code: d={“col1″:[1,2,3],”col2”:[“A”,”B”,”C”]} df=pd.DataFrame(d) df.dropna(inplace=True) df=df[df.col1!=1] df
Output:
50. What is reindexing in pandas?
Reindexing is the process of re-assigning the index of a pandas data frame.
51. What exactly do you mean when you say “lambda function”?
A lambda function is a type of anonymous function. This function can take as many parameters as you want, but just one statement.
Lambda is typically utilized in instances where an anonymous function is required for a short period of time. Lambda functions can be applied in two different ways:
- Assigning Lambda functions to a variable
- Wrapping Lambda function into another function
Create a lambda function that prints the total of all the elements in this list -> [5, 8, 10, 20, 50, 100].
A lambda function is an anonymous function (a function that does not have a name) in Python. To define anonymous functions, we use the ‘lambda’ keyword instead of the ‘def’ keyword, hence the name ‘lambda function’. Lambda functions can have any number of arguments but only one statement.
<code>from functools import reduce sequences = [5, 8, 10, 20, 50, 100] sum = reduce
(lambda x, y: x+y, sequences) print(sum)</code>
52. What is vstack() in numpy? Give an example
vstack() is a function to align rows vertically. All rows must have the same number of elements.
53. How do we interpret Python?
When a python program is written, it converts the source code written by the developer into an intermediate language, which is then converted into machine language that needs to be executed.
54. How to remove spaces from a string in Python?
Spaces can be removed from a string in python by using strip() or replace() functions. Strip() function is used to remove the leading and trailing white spaces while the replace() function is used to remove all the white spaces in the string.
To Remove All Leading Whitespace in a String
Python provides the inbuilt function lstrip() to remove all leading spaces from a string.
>>“ Python”.lstrip
Output: Python
55. Explain the file processing modes that Python supports.
There are three file processing modes in Python: read-only(r), write-only(w), read-write(rw) and append (a). So, if you are opening a text file in say, read mode. The preceding modes become “rt” for read-only, “wt” for write, and so on. Similarly, a binary file can be opened by specifying “b” along with the file accessing flags (“r”, “w”, “rw”, and “a”) preceding it.
56. How is memory managed in Python?
Memory management in python comprises a private heap containing all objects and data structure. The heap is managed by the interpreter and the programmer does not have access to it at all. The Python memory manager does all the memory allocation. Moreover, there is an inbuilt garbage collector that recycles and frees memory for the heap space.
57. What is a unit test in Python?
Unit test is a unit testing framework in Python. It supports sharing of setup and shutdown code for tests, aggregation of tests into collections, test automation, and independence of the tests from the reporting framework.
58. How do you delete a file in Python?
Files can be deleted in Python by using the command os.remove (filename) or os.unlink(filename)
Use command os.remove(file_name) to delete a file in Python.
59. How do you create an empty class in Python?
To create an empty class we can use the pass command after the definition of the class object. A pass is a statement in Python that does nothing.
60. What are Python decorators?
Decorators are functions that take another function as an argument to modify its behavior without changing the function itself. These are useful when we want to dynamically increase the functionality of a function without changing it.
61. You have this covid-19 dataset below:
From this dataset, how will you make a bar-plot for the top 5 states having maximum confirmed cases as of 17=07-2020?
sol: #keeping only required columns df = df[[‘Date’, ‘State/UnionTerritory’,’Cured’,’Deaths’,’Confirmed’]] #renaming column names df.columns = [‘date’, ‘state’,’cured’,’deaths’,’confirmed’] #current date today = df[df.date == ‘2020-07-17’] #Sorting data w.r.t number of confirmed cases max_confirmed_cases=today.sort_values(by=”confirmed”,ascending=False) max_confirmed_cases #Getting states with maximum number of confirmed cases top_states_confirmed=max_confirmed_cases[0:5] #Making bar-plot for states with top confirmed cases sns.set(rc={‘figure.figsize’:(15,10)}) sns.barplot(x=”state”,y=”confirmed”,data=top_states_confirmed,hue=”state”) plt.show()
62. From this covid-19 dataset:
How can you make a bar plot for the top-5 states with the most amount of deaths?
Sol: max_death_cases=today.sort_values(by=”deaths”,ascending=False) max_death_cases sns.set(rc={‘figure.figsize’:(15,10)}) sns.barplot(x=”state”,y=”deaths”,data=top_states_death,hue=”state”) plt.show()
63. In Python, what is “self”?
Self is a class instance or an object. In Python, this is explicitly supplied as the first parameter. In Java, on the other hand, it is optional. With local variables, it makes it easier to distinguish between a class’s methods and attributes.
In the init method, the self variable refers to the newly created object, whereas it relates to the object whose method was called in other methods.
Self is used to represent the class instance. In Python, you can access the class’s attributes and methods with this keyword. It connects the attributes to the arguments. Self appears in a variety of contexts and is frequently mistaken for a term. Self is not a keyword in Python, unlike in C++.
64. What is the difference between the methods append() and extend()?
The methods append() and extend() are used to add elements to the end of a list.
append(element): Adds the given element at the end of the list that called this append() method
extend(another-list): Adds the elements of another list at the end of the list that called this extend() method
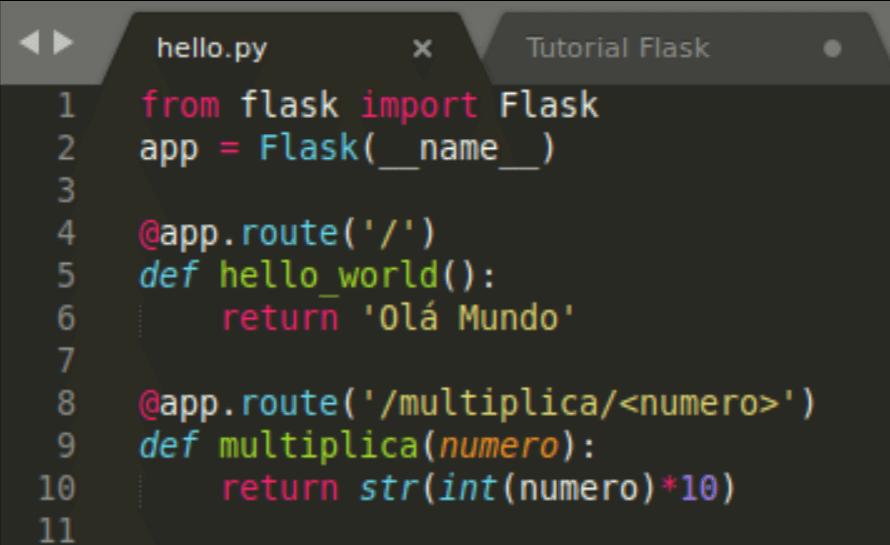
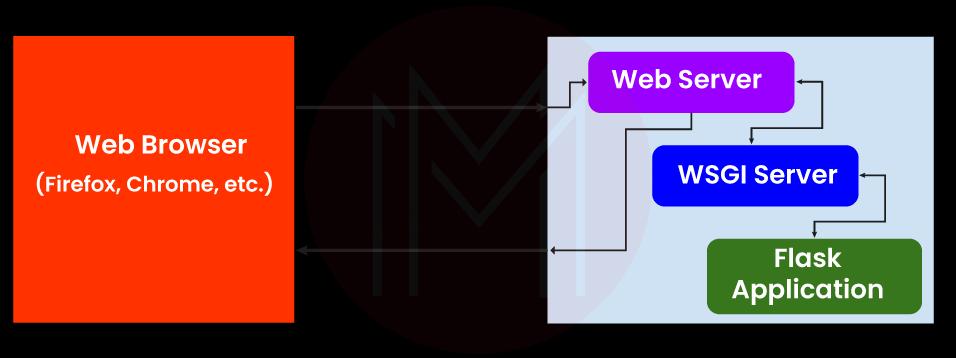
65. How does Python Flask handle database requests?
Flask supports a database-powered application (RDBS). Such a system requires creating a schema, which needs piping the schema.sql file into the sqlite3 command. Python developers need to install the sqlite3 command to create or initiate the database in Flask.
Flask allows to request for a database in three ways:
- before_request(): They are called before a request and pass no arguments.
- after_request(): They are called after a request and pass the response that will be sent to the client.
- teardown_request(): They are called in a situation when an exception is raised and responses are not guaranteed. They are called after the response has been constructed. They are not allowed to modify the request, and their values are ignored.
66. In Python, what exactly is docstring?
The string literals encased in triple quotes that come right after the definition of a function, method, class, or module are called Python docstrings. The functionality of a function, method, class, or module is typically described using these terms. Using the __doc__ attribute, we may retrieve these docstrings.
This is one of the most frequently asked Python interview questions
Docstrings are used in providing documentation to various Python modules, classes, functions, and methods.
Example –
def add(a,b):
” ” “This function adds two numbers.” ” ”
sum=a+b
return sum
sum=add(10,20)
print(“Accessing doctstring method 1:”,add.__doc__)
print(“Accessing doctstring method 2:”,end=””)
help(add)
Output –
Accessing docstring method 1: This function adds two numbers.
Accessing docstring method 2: Help on function add-in module __main__:
add(a, b)
This function adds two numbers.
Docstrings are documentation strings. Within triple quotations are these docstrings. They are not allocated to any variable and, as a result, they can also be used as comments.
67. How is Multithreading achieved in Python?
Python has a multi-threading package, but commonly not considered good practice to use it as it will result in increased code execution time.
- Python has a constructor called the Global Interpreter Lock (GIL). The GIL ensures that only one of your ‘threads’ can execute at one time. The process makes sure that a thread acquires the GIL, does a little work, then passes the GIL onto the next thread.
- This happens at a very Quick instance of time and that’s why to the human eye it seems like your threads are executing parallelly, but in reality, they are executing one by one by just taking turns using the same CPU core.
Multithreading usually implies that multiple threads are executed concurrently. The Python Global Interpreter Lock doesn’t allow more than one thread to hold the Python interpreter at that particular point of time. So multithreading in python is achieved through context switching. It is quite different from multiprocessing which actually opens up multiple processes across multiple threads.
Although Python includes a multi-threading module, it is usually not a good idea to utilize it if you want to multi-thread to speed up your code.
As this happens so quickly, it may appear to the human eye that your threads are running in parallel, but they are actually sharing the same CPU core.
The Global Interpreter Lock is a Python concept (GIL). Only one of your ‘threads’ can execute at a moment, thanks to the GIL. A thread obtains the GIL, performs some work, and then passes the GIL to the following thread.
68. What is slicing in Python?
Slicing is a process used to select a range of elements from sequence data types like list, string, and tuple. Slicing is beneficial and easy to extract out the elements. It requires a : (colon) which separates the start index and end index of the field. All the data sequence types List or tuple allows us to use slicing to get the needed elements. Although we can get elements by specifying an index, we get only a single element whereas using slicing we can get a group or appropriate range of needed elements.
69. What is functional programming? Does Python follow a functional programming style? If yes, list a few methods to implement functionally oriented programming in Python.
Functional programming is a coding style where the main source of logic in a program comes from functions.
Incorporating functional programming in our codes means writing pure functions.
Pure functions are functions that cause little or no changes outside the scope of the function. These changes are referred to as side effects. To reduce side effects, pure functions are used, which makes the code easy to follow, test, or debug.
70. Which one of the following is not the correct syntax for creating a set in Python?
- set([[1,2],[3,4],[4,5]])
- set([1,2,2,3,4,5])
- {1,2,3,4}
- set((1,2,3,4))
set([[1,2],[3,4],[4,5]])
Explanation: The argument given for the set must be iterable.
71. What is the difference between / and // operator in Python?
- /: is a division operator and returns the Quotient value.
10/3
3.33
- //: is known as floor division operator and used to return only the value of quotient before the decimal
10//3
3
72. What is the easiest way to calculate percentiles when using Python?
The easiest and the most efficient way you can calculate percentiles in Python is to make use of NumPy arrays and its functions.
73. What is a palindrome number?
A palindrome is a word, phrase, or sequence that reads the same forward as it does backward, such as madam, nurses run, and so on.
74. What is slicing in python?
Slicing is used to access parts of sequences like lists, tuples, and strings. The syntax of slicing is -[start:end:step]. The step can be omitted as well. When we write [start:end] this returns all the elements of the sequence from the start (inclusive) till the end-1 element. If the start or end element is negative i, it means the ith element from the end. The step indicates the jump or how many elements have to be skipped. Eg. if there is a list- [1,2,3,4,5,6,7,8]. Then [-1:2:2] will return elements starting from the last element till the third element by printing every second element.i.e. [8,6,4].
75. What are Keywords in Python?
Keywords in python are reserved words that have special meanings. They are generally used to define types of variables. Keywords cannot be used for variable or function names. There are the following 33 keywords in python –
- And
- Or
- Not
- If
- Elif
- Else
- For
- While
- Break
- As
- Def
- Lambda
- Pass
- Return
- True
- False
- Try
- With
- Assert
- Class
- Continue
- Del
- Except
- Finally
- From
- Global
- Import
- In
- Is
- None
- Nonlocal
- Raise
- Yield
76. What are the new features added in Python 3.9.0.0 version?
The new features in Python 3.9.0.0 version are-
- New Dictionary functions Merge(|) and Update(|=)
- New String Methods to Remove Prefixes and Suffixes
- Type Hinting Generics in Standard Collections
- New Parser based on PEG rather than LL1
- New modules like zoneinfo and graphlib
- Improved Modules like ast, asyncio, etc.
- Optimizations such as optimized idiom for assignment, signal handling, optimized python built ins, etc.
- Deprecated functions and commands such as deprecated parser and symbol modules, deprecated functions, etc.
- Removal of erroneous methods, functions, etc.
77. How is memory managed in Python?
Memory is managed in Python in the following ways:
Memory management in python is managed by Python private heap space. All Python objects and data structures are located in a private heap. The programmer does not have access to this private heap. The python interpreter takes care of this instead.
The allocation of heap space for Python objects is done by Python’s memory manager. The core API gives access to some tools for the programmer to code.
Python also has an inbuilt garbage collector, which recycles all the unused memory and so that it can be made available to the heap space.
Python has a private heap space that stores all the objects. The Python memory manager regulates various aspects of this heap, such as sharing, caching, segmentation, and allocation. The user has no control over the heap; only the Python interpreter has access.
- Python’s private heap space is in charge of memory management. A private heap holds all Python objects and data structures. This secret heap is not accessible to the programmer. Instead, the Python interpreter takes care of it.
- Python also includes a built-in garbage collector, which recycles all unused memory and makes it available to the heap space.
- Python’s memory management is in charge of allocating heap space for Python objects. The core API allows programmers access to some programming tools.
78. What is namespace in Python?
A namespace is a naming system used to make sure that names are unique to avoid naming conflicts.
79. What is PYTHONPATH?
It is an environment variable that is used when a module is imported. Whenever a module is imported, PYTHONPATH is also looked up to check for the presence of the imported modules in various directories. The interpreter uses it to determine which module to load.
80. What are python modules? Name some commonly used built-in modules in Python?
Python modules are files containing Python code. This code can either be functions classes or variables. A Python module is a .py file containing executable code.
Some of the commonly used built-in modules are:
- os
- sys
- math
- random
- data time
- JSON
81. How to remove values to a python array?
Elements can be removed from the python array using pop() or remove() methods.
pop(): This function will return the removed element.
remove(): It will not return the removed element.
82. What are Python libraries? Name a few of them.
Python libraries are a collection of Python packages. Some of the majorly used python libraries are – Numpy, Pandas, Matplotlib, Scikit-learn, and many more.
83. How do you do data abstraction in Python?
Data Abstraction is providing only the required details and hiding the implementation from the world. It can be achieved in Python by using interfaces and abstract classes.
84. What does an object() do?
It returns a featureless object that is a base for all classes. Also, it does not take any parameters.
85. What is the Difference Between a Shallow Copy and Deep Copy?
Deepcopy creates a different object and populates it with the child objects of the original object. Therefore, changes in the original object are not reflected in the copy.
copy.deepcopy() creates a Deep Copy.
Shallow copy creates a different object and populates it with the references of the child objects within the original object. Therefore, changes in the original object are reflected in the copy.
copy.copy creates a Shallow Copy.
86. What Advantage Does the Numpy Array Have over a Nested List?
Numpy is written in C so that all its complexities are backed into a simple to use a module. Lists, on the other hand, are dynamically typed. Therefore, Python must check the data type of each element every time it uses it. This makes Numpy arrays much faster than lists.
Numpy has a lot of additional functionality that list doesn’t offer; for instance, a lot of things can be automated in Numpy.
87. What are Pickling and Unpickling?
| Pickling |
Unpickling |
- Converting a Python object hierarchy to a byte stream is called pickling
- Pickling is also referred to as serialization
|
- Converting a byte stream to a Python object hierarchy is called unpickling
- Unpickling is also referred to as deserialization
|
If you just created a neural network model, you can save that model to your hard drive, pickle it, and then unpickle to bring it back into another software program or to use it at a later time.
Pickling is the process of converting a Python object hierarchy into a byte stream for storing it into a database. It is also known as serialization. Unpickling is the reverse of pickling. The byte stream is converted back into an object hierarchy.
The Pickle module takes any Python object and converts it to a string representation, which it then dumps into a file using the dump method. This is known as pickling. Unpickling is the process of recovering original Python objects from a stored text representation.
88. Are Arguments in Python Passed by Value or by Reference?
Arguments are passed in python by a reference. This means that any changes made within a function are reflected in the original object.
Consider two sets of code shown below:
In the first example, we only assigned a value to one element of ‘l’, so the output is [3, 2, 3, 4].
In the second example, we have created a whole new object for ‘l’. But, the values [3, 2, 3, 4] doesn’t show up in the output as it is outside the definition of the function.
89. How Would You Generate Random Numbers in Python?
To generate random numbers in Python, you must first import the random module.
The random() function generates a random float value between 0 & 1.
> random.random()
The randrange() function generates a random number within a given range.
Syntax: randrange(beginning, end, step)
Example – > random.randrange(1,10,2)
90. What Does the // Operator Do?
In Python, the / operator performs division and returns the quotient in the float.
For example: 5 / 2 returns 2.5
The // operator, on the other hand, returns the quotient in integer.
For example: 5 // 2 returns 2
91. What Does the ‘is’ Operator Do?
The ‘is’ operator compares the id of the two objects.
list1=[1,2,3]
list2=[1,2,3]
list3=list1
list1 == list2 🡪 True
list1 is list2 🡪 False
list1 is list3 🡪 True
92. How Will You Check If All the Characters in a String Are Alphanumeric?
Python has an inbuilt method isalnum() which returns true if all characters in the string are alphanumeric.
Example –
>> “abcd123”.isalnum()
Output: True
>>”abcd@123#”.isalnum()
Output: False
Another way is to use regex as shown.
>>import re
>>bool(re.match(‘[A-Za-z0-9]+$’,’abcd123’))
Output: True
>> bool(re.match(‘[A-Za-z0-9]+$’,’abcd@123’))
Output: False
93. How Will You Merge Elements in a Sequence?
There are three types of sequences in Python:
Example of Lists –
>>l1=[1,2,3]
>>l2=[4,5,6]
>>l1+l2
Output: [1,2,3,4,5,6]
Example of Tuples –
>>t1=(1,2,3)
>>t2=(4,5,6)
>>t1+t2
Output: (1,2,3,4,5,6)
Example of String –
>>s1=“Simpli”
>>s2=“learn”
>>s1+s2
Output: ‘Simplilearn’
94. How Would You Replace All Occurrences of a Substring with a New String?
The replace() function can be used with strings for replacing a substring with a given string. Syntax:
str.replace(old, new, count)
replace() returns a new string without modifying the original string.
Example –
>>”Hey John. How are you, John?”.replace(“john”,“John”,1)
Output: “Hey John. How are you, John?
95.What Is the Difference Between Del and Remove() on Lists?
| del |
remove() |
- del removes all elements of a list within a given range
- Syntax: del list[start:end]
|
- remove() removes the first occurrence of a particular character
- Syntax: list.remove(element)
|
Here is an example to understand the two statements –
>>lis=[‘a’, ‘b’, ‘c’, ‘d’]
>>del lis[1:3]
>>lis
Output: [“a”,”d”]
>>lis=[‘a’, ‘b’, ‘b’, ‘d’]
>>lis.remove(‘b’)
>>lis
Output: [‘a’, ‘b’, ‘d’]
Note that in the range 1:3, the elements are counted up to 2 and not 3.
96. How Do You Display the Contents of a Text File in Reverse Order?
You can display the contents of a text file in reverse order using the following steps:
- Open the file using the open() function
- Store the contents of the file into a list
- Reverse the contents of the list
- Run a for loop to iterate through the list
97. Differentiate Between append() and extend().
| append() |
extend() |
- append() adds an element to the end of the list
- Example –
>>lst=[1,2,3]
>>lst.append(4)
>>lst
Output:[1,2,3,4] |
- extend() adds elements from an iterable to the end of the list
- Example –
>>lst=[1,2,3]
>>lst.extend([4,5,6])
>>lst
Output:[1,2,3,4,5,6] |
98. What Is the Output of the below Code? Justify Your Answer.
>>def addToList(val, list=[]):
>> list.append(val)
>> return list
>>list1 = addToList(1)
>>list2 = addToList(123,[])
>>list3 = addToList(‘a’)
>>print (“list1 = %s” % list1)
>>print (“list2 = %s” % list2)
>>print (“list3 = %s” % list3)
Output:
list1 = [1,’a’]
list2 = [123]
lilst3 = [1,’a’]
Note that list1 and list3 are equal. When we passed the information to the addToList, we did it without a second value. If we don’t have an empty list as the second value, it will start off with an empty list, which we then append. For list2, we appended the value to an empty list, so its value becomes [123].
For list3, we’re adding ‘a’ to the list. Because we didn’t designate the list, it is a shared value. It means the list doesn’t reset and we get its value as [1, ‘a’].
Remember that a default list is created only once during the function and not during its call number.
99. What Is the Difference Between a List and a Tuple?
Lists are mutable while tuples are immutable.
Example:
List
>>lst = [1,2,3]
>>lst[2] = 4
>>lst
Output:[1,2,4]
Tuple
>>tpl = (1,2,3)
>>tpl[2] = 4
>>tpl
Output:TypeError: ‘tuple’
the object does not support item
assignment
There is an error because you can’t change the tuple 1 2 3 into 1 2 4. You have to completely reassign tuple to a new value.
100. How Do You Use Print() Without the Newline?
The solution to this depends on the Python version you are using.
Python v2
>>print(“Hi. ”),
>>print(“How are you?”)
Output: Hi. How are you?
Python v3
>>print(“Hi”,end=“ ”)
>>print(“How are you?”)
Output: Hi. How are you?
101.Is Python Object-oriented or Functional Programming?
Python is considered a multi-paradigm language.
Python follows the object-oriented paradigm
- Python allows the creation of objects and their manipulation through specific methods
- It supports most of the features of OOPS such as inheritance and polymorphism
Python follows the functional programming paradigm
- Functions may be used as the first-class object
- Python supports Lambda functions which are characteristic of the functional paradigm
102. Write a Function Prototype That Takes a Variable Number of Arguments.
The function prototype is as follows:
def function_name(*list)
>>def fun(*var):
>> for i in var:
print(i)
>>fun(1)
>>fun(1,25,6)
In the above code, * indicates that there are multiple arguments of a variable.
103. What Are *args and *kwargs?
*args
- It is used in a function prototype to accept a varying number of arguments.
- It’s an iterable object.
- Usage – def fun(*args)
- The function definition uses the *args syntax to pass variable-length parameters.
- “*” denotes variable length, while “args” is the standard name. Any other will suffice.
*kwargs
- It is used in a function prototype to accept the varying number of keyworded arguments.
- It’s an iterable object
- Usage – def fun(**kwargs):
- **kwargs is a special syntax for passing variable-length keyworded arguments to functions.
- When a variable is passed to a function, it is called a keyworded argument.
- “Kwargs” is also used by convention here. You are free to use any other name.
fun(colour=”red”.units=2)
104. “in Python, Functions Are First-class Objects.” What Do You Infer from This?
It means that a function can be treated just like an object. You can assign them to variables, or pass them as arguments to other functions. You can even return them from other functions.
105. What Is the Output Of: Print(__name__)? Justify Your Answer.
__name__ is a special variable that holds the name of the current module. Program execution starts from main or code with 0 indentations. Thus, __name__ has a value __main__ in the above case. If the file is imported from another module, __name__ holds the name of this module.
106. What Is a Numpy Array?
A numpy array is a grid of values, all of the same type, and is indexed by a tuple of non-negative integers. The number of dimensions determines the rank of the array. The shape of an array is a tuple of integers giving the size of the array along each dimension.
107. What Is the Difference Between Matrices and Arrays?
| Matrices |
Arrays |
- A matrix comes from linear algebra and is a two-dimensional representation of data
- It comes with a powerful set of mathematical operations that allow you to manipulate the data in interesting ways
|
- An array is a sequence of objects of similar data type
- An array within another array forms a matrix
|
108. How Do You Get Indices of N Maximum Values in a Numpy Array?
>>import numpy as np
>>arr=np.array([1, 3, 2, 4, 5])
>print(arr.argsort( ) [ -N: ][: : -1])
109. How Would You Obtain the Res_set from the Train_set and the Test_set from Below?
>>train_set=np.array([1, 2, 3])
>>test_set=np.array([[0, 1, 2], [1, 2, 3])
Res_set 🡪 [[1, 2, 3], [0, 1, 2], [1, 2, 3]]
Choose the correct option:
- res_set = train_set.append(test_set)
- res_set = np.concatenate([train_set, test_set]))
- resulting_set = np.vstack([train_set, test_set])
- None of these
Here, options a and b would both do horizontal stacking, but we want vertical stacking. So, option c is the right statement.
resulting_set = np.vstack([train_set, test_set])
110. You Have Uploaded the Dataset in Csv Format on Google Spreadsheet and Shared It Publicly. How Can You Access This in Python?
We can use the following code:
>>link = https://docs.google.com/spreadsheets/d/…
>>source = StringIO.StringIO(requests.get(link).content))
>data = pd.read_csv(source)
111. What Is the Difference Between the Two Data Series given Below?
df[‘Name’] and df.loc[:, ‘Name’], where:
df = pd.DataFrame([‘aa’, ‘bb’, ‘xx’, ‘uu’], [21, 16, 50, 33], columns = [‘Name’, ‘Age’])
Choose the correct option:
- 1 is the view of original dataframe and 2 is a copy of original dataframe
- 2 is the view of original dataframe and 1 is a copy of original dataframe
- Both are copies of original dataframe
- Both are views of original dataframe
Answer – 3. Both are copies of the original dataframe.
112. You Get the Error “temp.Csv” While Trying to Read a File Using Pandas. Which of the Following Could Correct It?
Error:
Traceback (most recent call last): File “<input>”, line 1, in<module> UnicodeEncodeError:
‘ascii’ codec can’t encode character.
Choose the correct option:
- pd.read_csv(“temp.csv”, compression=’gzip’)
- pd.read_csv(“temp.csv”, dialect=’str’)
- pd.read_csv(“temp.csv”, encoding=’utf-8′)
- None of these
The error relates to the difference between utf-8 coding and a Unicode.
So option 3. pd.read_csv(“temp.csv”, encoding=’utf-8′) can correct it.
113. How Do You Set a Line Width in the Plot given Below?
>>import matplotlib.pyplot as plt
>>plt.plot([1,2,3,4])
>>plt.show()
Choose the correct option:
- In line two, write plt.plot([1,2,3,4], width=3)
- In line two, write plt.plot([1,2,3,4], line_width=3
- In line two, write plt.plot([1,2,3,4], lw=3)
- None of these
Answer – 3. In line two, write plt.plot([1,2,3,4], lw=3)
114. How Would You Reset the Index of a Dataframe to a given List? Choose the Correct Option.
- df.reset_index(new_index,)
- df.reindex(new_index,)
- df.reindex_like(new_index,)
- None of these
Answer – 3. df.reindex_like(new_index,)
115. How Can You Copy Objects in Python?
The function used to copy objects in Python are:
copy.copy for shallow copy and
copy.deepcopy() for deep copy
The assignment statement (= operator) in Python does not copy objects. Instead, it establishes a connection between the existing object and the name of the target variable. The copy module is used to make copies of an object in Python. Furthermore, the copy module provides two options for producing copies of a given object –
Deep Copy: Deep Copy recursively replicates all values from source to destination object, including the objects referenced by the source object.
from copy import copy, deepcopy
list_1 = [1, 2, [3, 5], 4]
## shallow copy
list_2 = copy(list_1)
list_2[3] = 7
list_2[2].append(6)
list_2 # output => [1, 2, [3, 5, 6], 7]
list_1 # output => [1, 2, [3, 5, 6], 4]
## deep copy
list_3 = deepcopy(list_1)
list_3[3] = 8
list_3[2].append(7)
list_3 # output => [1, 2, [3, 5, 6, 7], 8]
list_1 # output => [1, 2, [3, 5, 6], 4]
Shallow Copy: A bit-wise copy of an object is called a shallow copy. The values in the copied object are identical to those in the original object. If one of the values is a reference to another object, only its reference addresses are copied.
When a new instance type is formed, a shallow copy is used to maintain the values that were copied in the previous instance. Shallow copy is used to copy reference pointers in the same way as values are copied. These references refer to the original objects, and any modifications made to any member of the class will have an impact on the original copy. Shallow copy enables faster program execution and is dependent on the size of the data being utilized.
Deep copy is a technique for storing previously copied values. The reference pointers to the objects are not copied during deep copy. It creates a reference to an object and stores the new object that is referenced to by another object. The changes made to the original copy will have no effect on any subsequent copies that utilize the item. Deep copy slows down program performance by creating many copies of each object that is called.
116. What Is the Difference Between range() and xrange() Functions in Python?
In terms of functionality, xrange and range are essentially the same. They both provide you the option of generating a list of integers to use whatever you want. The sole difference between range and xrange is that range produces a Python list object whereas x range returns an xrange object. This is especially true if you are working with a machine that requires a lot of memory, such as a phone because range will utilize as much memory as it can to generate your array of numbers, which can cause a memory error and crash your program. It is a beast with a memory problem.
| range() |
xrange() |
- range returns a Python list object
|
- xrange returns an xrange object
|
117. How Can You Check Whether a Pandas Dataframe Is Empty or Not?
The attribute df.empty is used to check whether a pandas data frame is empty or not.
>>import pandas as pd
>>df=pd.DataFrame({A:[]})
>>df.empty
Output: True
118. Write a Code to Sort an Array in Numpy by the (N-1)Th Column.
This can be achieved by using argsort() function. Let us take an array X; the code to sort the (n-1)th column will be x[x [: n-2].argsoft()]
The code is as shown below:
>>import numpy as np
>>X=np.array([[1,2,3],[0,5,2],[2,3,4]])
>>X[X[:,1].argsort()]
Output:array([[1,2,3],[0,5,2],[2,3,4]])
119. How Do You Create a Series from a List, Numpy Array, and Dictionary?
The code is as shown:
>> #Input
>>import numpy as np
>>import pandas as pd
>>mylist = list(‘abcedfghijklmnopqrstuvwxyz’)
>>myarr = np.arange(26)
>>mydict = dict(zip(mylist, myarr))
>> #Solution
>>ser1 = pd.Series(mylist)
>>ser2 = pd.Series(myarr)
>>ser3 = pd.Series(mydict)
>print(ser3.head())
120. How Do You Get the Items Not Common to Both Series a and Series B?
>> #Input
>>import pandas as pd
>>ser1 = pd.Series([1, 2, 3, 4, 5])
>>ser2 = pd.Series([4, 5, 6, 7, 8])
>> #Solution
>>ser_u = pd.Series(np.union1d(ser1, ser2)) # union
>>ser_i = pd.Series(np.intersect1d(ser1, ser2)) # intersect
>ser_u[~ser_u.isin(ser_i)]
121. How Do You Keep Only the Top Two Most Frequent Values as It Is and Replace Everything Else as ‘other’ in a Series?
>> #Input
>>import pandas as pd
>>np.random.RandomState(100)
>>ser = pd.Series(np.random.randint(1, 5, [12]))
>> #Solution
>>print(“Top 2 Freq:”, ser.value_counts())
>>ser[~ser.isin(ser.value_counts().index[:2])] = ‘Other’
>ser
122. How Do You Find the Positions of Numbers That Are Multiples of Three from a Series?
>> #Input
>>import pandas as pd
>>ser = pd.Series(np.random.randint(1, 10, 7))
>>ser
>> #Solution
>>print(ser)
>np.argwhere(ser % 3==0)
123. How Do You Compute the Euclidean Distance Between Two Series?
The code is as shown:
>> #Input
>>p = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
>>q = pd.Series([10, 9, 8, 7, 6, 5, 4, 3, 2, 1])
>> #Solution
>>sum((p – q)**2)**.5
>> #Solution using func
>>np.linalg.norm(p-q)
You can see that the Euclidean distance can be calculated using two ways.
124. Which Python Library Is Built on Top of Matplotlib and Pandas to Ease Data Plotting?
Seaborn is a Python library built on top of matplotlib and pandas to ease data plotting. It is a data visualization library in Python that provides a high-level interface for drawing statistical informative graphs.
Did you know the answers to these Python interview questions? If not, here is what you can do.
125. What are the important features of Python?
- Python is a scripting language. Python, unlike other programming languages like C and its derivatives, does not require compilation prior to execution.
- Python is dynamically typed, which means you don’t have to specify the kinds of variables when declaring them or anything.
- Python is well suited to object-oriented programming since it supports class definition, composition, and inheritance.
126. What is PEP 8?
PEP denotes Python Enhancement Proposal. It’s a collection of guidelines for formatting Python code for maximum readability.
127. Explain Python namespace.
In Python, a namespace refers to the name that is assigned to each object.
128. What are decorators in Python?
Decorators are used for changing the appearance of a function without changing its structure. Decorators are typically defined prior to the function they are enhancing.
Decorators are typically defined prior to the function they are enhancing. To use a decorator, we must first specify its function. Then we write the function to which it is applied, simply placing the decorator function above the function to which it must be applied.
129. What is slicing and how to use in Python?
Slicing is a technique for gaining access to specific bits of sequences such as strings, tuples, and lists.
Slicing is a technique for gaining access to specific bits of sequences such as lists, tuples, and strings. The slicing syntax is [start:end:step]. This step can also be skipped. [start:end] returns all sequence items from the start (inclusive) to the end-1 element. It means the ith element from the end of the start or end element is negative i. The step represents the jump or the number of components that must be skipped.
130. How to combine dataframes in Pandas?
The following are the ways through which the data frames in Pandas can be combined:
- Concatenating them by vertically stacking the two dataframes.
- Concatenating them by horizontally stacking the two dataframes.
- Combining them on a common column. This is referred to as joining.
The concat() function is used to concatenate two dataframes. Its syntax is- pd.concat([dataframe1, dataframe2]).
Dataframes are joined together on a common column called a key. When we combine all the rows in data frame it is union and the join used is outer join. While, when we combine the common rows or intersection, the join used is the inner join. Its syntax is- pd.concat([dataframe1, dataframe2], axis=’axis’, join=’type_of_join)
This function is used for the horizontal stacking of data frames.
- concat(): This function is used for vertical stacking and best suites when the data frames to be combined possess the same column and similar fields.
- join(): This function is used to extract data from different data frames which have one or more columns common.
131. What are the key features of the Python 3.9.0.0 version?
- Zoneinfo and graphlib are two new modules.
- Improved modules such as asyncio and ast.
- Optimizations include improved idiom for assignment, signal handling, and Python built-ins.
- Removal of erroneous methods and functions.
- Instead of LL1, a new parser is based on PEG.
- Remove Prefixes and Suffixes with New String Methods.
- Generics with type hinting in standard collections.
132. Explain global variables and local variables in Python.
Local Variables:
A local variable is any variable declared within a function. This variable exists only in local space, not in global space.
Global Variables:
Global variables are variables declared outside of a function or in a global space. Any function in the program can access these variables.
133. How to install Python on Windows and set path variables?
- Download Python from https://www.python.org/downloads/
- Install it on your computer. Using your command prompt, look for the location where PYTHON is installed on your computer by typing cmd python.
- Then, in advanced system settings, create a new variable called PYTHON_NAME and paste the copied path into it.
- Search the path variable, choose its value and select ‘edit’.
- If the value doesn’t have a semicolon at the end, add one, and then type %PYTHON HOME%.
134. Is it necessary to indent in Python?
Indentation is required in Python. It designates a coding block. An indented block contains all of the code for loops, classes, functions, and so on. Typically, four space characters are used. Your code will not execute correctly if it is not indented, and it will also generate errors.
135. On Unix, how do you make a Python script executable?
Script file should start with #!/usr/bin/env python.
136. What are literals and the types of literals in Python?
For primitive data types, a literal in Python source code indicates a fixed value.
For primitive data types, a literal in Python source code indicates a fixed value. Following are the 5 types of literal in Python:
- String Literal: A string literal is formed by assigning some text to a variable that is contained in single or double-quotes. Assign the multiline text encased in triple quotes to produce multiline literals.
- Numeric Literal: They may contain numeric values that are floating-point values, integers, or complex numbers.
- Character Literal: It is made by putting a single character in double-quotes.
- Boolean Literal: True or False
- Literal Collections: There are four types of literals such as list collections, tuple literals, set literals, dictionary literals, and set literals.
137. How does continue, break, and pass work?
| Continue |
When a specified condition is met, the control is moved to the beginning of the loop, allowing some parts of the loop to be transferred. |
| Break |
When a condition is met, the loop is terminated and control is passed to the next statement. |
| Pass |
When you need a piece of code syntactically but don’t want to execute it, use this. This is a null operation. |
138. In Python, are arguments provided by value or reference?
Pass by value: The actual item’s copy is passed. Changing the value of the object’s copy has no effect on the original object’s value.
Pass by reference: The actual object is passed as a reference. The value of the old object will change if the value of the new object is changed.
Arguments are passed by reference in Python.
def appendNumber(arr):
arr.append(4)
arr = [1, 2, 3]
print(arr) #Output: => [1, 2, 3]
appendNumber(arr)
print(arr) #Output: => [1, 2, 3, 4]
139. Explain join() and split() functions in Python.
The join() function can be used to combine a list of strings based on a delimiter into a single string.
The split() function can be used to split a string into a list of strings based on a delimiter.
string = “This is a string.”
string_list = string.split(‘ ‘) #delimiter is ‘space’ character or ‘ ‘
print(string_list) #output: [‘This’, ‘is’, ‘a’, ‘string.’]
print(‘ ‘.join(string_list)) #output: This is a string.
140. What are negative indexes and why are they used?
- The indexes from the end of the list, tuple, or string are called negative indexes.
- Arr[-1] denotes the array’s last element. Arr[]
141. In Python, how do you remark numerous lines?
Comments that involve multiple lines are known as multi-line comments. A # must prefix all lines that will be commented. You can also use a convenient shortcut to remark several lines. All you have to do is hold down the ctrl key and left-click anywhere you want a # character to appear, then input a # once. This will add a comment to every line where you put your cursor.
142. What is the purpose of ‘not’, ‘is’, and ‘in’ operators?
Special functions are known as operators. They take one or more input values and output a result.
not- returns the boolean value’s inverse
is- returns true when both operands are true
in- determines whether a certain element is present in a series
143. What are the functions help() and dir() used for in Python?
Both help() and dir() are available from the Python interpreter and are used to provide a condensed list of built-in functions.
dir() function: The defined symbols are displayed using the dir() function.
help() function: The help() function displays the documentation string and also allows you to access help for modules, keywords, attributes, and other items.
144. Why isn’t all the memory de-allocated when Python exits?
- When Python quits, some Python modules, especially those with circular references to other objects or objects referenced from global namespaces, are not necessarily freed or deallocated.
- Python would try to de-allocate/destroy all other objects on exit because it has its own efficient cleanup mechanism.
- It is difficult to de-allocate memory that has been reserved by the C library.
145. In Python, how do you utilize ternary operators?
The Ternary operator is the operator for displaying conditional statements. This is made of true or false values and a statement that must be evaluated.
146. Explain the split(), sub(), and subn() methods of the Python “re” module.
Python’s “re” module provides three ways for modifying strings. They are:
split (): a regex pattern is used to “separate” a string into a list
subn(): It works similarly to sub(), returning the new string as well as the number of replacements.
sub(): identifies all substrings that match the regex pattern and replaces them with a new string
147. What are negative indexes and why do we utilize them?
Python sequences are indexed, and they include both positive and negative values. Positive numbers are indexed with ‘0’ as the first index and ‘1’ as the second index, and so on.
The index for a negative number begins with ‘-1,’ which is the last index in the sequence, and ends with ‘-2,’ which is the penultimate index, and the sequence continues like a positive number. The negative index is used to eliminate all new-line spaces from the string and allow it to accept the last character S[:-1]. The negative index can also be used to represent the correct order of the string.
148. What are built-in types of Python?
Given below are the built-in types of Python:
- Built in functions
- Boolean
- String
- Complex numbers
- Floating point
- Integers
149. What are the benefits of NumPy arrays over (nested) Python lists?
- Lists in Python are useful general-purpose containers. They allow for (relatively) quick insertion, deletion, appending, and concatenation, and Python’s list comprehensions make them simple to create and operate.
- They have some limitations: they don’t enable “vectorized” operations like elementwise addition and multiplication, and because they can include objects of different types, Python must maintain type information for each element and execute type dispatching code while working on it.
- NumPy arrays are faster, and NumPy comes with a number of features, including histograms, algebra, linear, basic statistics, fast searching, convolutions, FFTs, and more.
150. What is the best way to add or remove values from a Python array?
The append(), extend(), and insert (i,x) procedures can be used to add elements to an array.y
The pop() and remove() methods can be used to remove elements from an array. The difference between these two functions is that one returns the removed value while the other does not.
151. Is there an object-oriented Programming (OOps) concept in Python?
Python is a computer language that focuses on objects. This indicates that by simply constructing an object model, every program can be solved in Python. Python, on the other hand, may be used as both a procedural and structured language.
152. Explain monkey patching in Python.
Monkey patches are solely used in Python to run-time dynamic updates to a class or module.
153. What is inheritance and different types of inheritance in Python?
Inheritance allows one class to gain all of another class’s members (for example, attributes and methods). Inheritance allows for code reuse, making it easier to develop and maintain applications.
The following are the various types of inheritance in Python:
- Single inheritance: The members of a single super class are acquired by a derived class.
- Multiple inheritance: More than one base class is inherited by a derived class.
- Muti-level inheritance: D1 is a derived class inherited from base1 while D2 is inherited from base2.
- Hierarchical Inheritance: You can inherit any number of child classes from a single base class.
154. Is multiple inheritance possible in Python?
A class can be inherited from multiple parent classes, which is known as multiple inheritance. In contrast to Java, Python allows multiple inheritance.
155. Explain polymorphism in Python.
The ability to take various forms is known as polymorphism. For example, if the parent class has a method named ABC, the child class can likewise have a method named ABC with its own parameters and variables. Python makes polymorphism possible.
156. What is encapsulation in Python?
Encapsulation refers to the joining of code and data. Encapsulation is demonstrated through a Python class.
157. In Python, how do you abstract data?
Only the necessary details are provided, while the implementation is hidden from view. Interfaces and abstract classes can be used to do this in Python.
158. Is access specifiers used in Python?
Access to an instance variable or function is not limited in Python. To imitate the behavior of protected and private access specifiers, Python introduces the idea of prefixing the name of the variable, function, or method with a single or double underscore.
159. How to create an empty class in Python?
A class that has no code defined within its block is called an empty class. The pass keyword can be used to generate it. You can, however, create objects of this class outside of the class. When used in Python, the PASS command has no effect.
160. What does an object() do?
It produces a featureless object that serves as the foundation for all classes. It also does not accept any parameters.
161. Write a Python program to generate a Star triangle.
| 1
2
3
4 |
def pyfunc(r):
for x in range(r):
print(‘ ‘*(r-x-1)+’*’*(2*x+1))
pyfunc(9) |
Output:
*
***
*****
*******
*********
***********
*************
***************
*****************
162. Write a program to produce the Fibonacci series in Python.
| 1
2
3
4
5
6
7
8
9
10
11
12 |
# Enter number of terms needednbsp;#0,1,1,2,3,5….
a=int(input(“Enter the terms”))
f=0;#first element of series
s=1#second element of series
if a=0:
print(“The requested series is”,f)
else:
print(f,s,end=” “)
for x in range(2,a):
print(next,end=” “)
f=s
s=next |
Output: Enter the terms 5 0 1 1 2 3
163. Make a Python program that checks if a sequence is a Palindrome.
a=input(“enter sequence”)
b=a[::-1]
if a==b:
print(“palindrome”)
else:
print(“Not a Palindrome”)
Output: enter sequence 323 palindrome
164. Make a one-liner that counts how many capital letters are in a file. Even if the file is too large to fit in memory, your code should work.
| 1
2
3
4
5
6 |
with open(SOME_LARGE_FILE) as fh:
count = 0
text = fh.read()
for character in text:
if character.isupper():
count += 1 |
Let us transform this into a single line
| 1 |
count sum(1 for line in fh for character in line if character.isupper())
|
165. Can you write a sorting algorithm with a numerical dataset?
| 1
2
3
4 |
list = [“1”, “4”, “0”, “6”, “9”]
list = [int(i) for i in list]
list.sort()
print (list) |
166. Check code given below, list the final value of A0, A1 …An.
| 1
2
3
4
5
6
7 |
A0 = dict(zip((‘a’,’b’,’c’,’d’,’e’),(1,2,3,4,5)))
A1 = range(10)A2 = sorted([i for i in A1 if i in A0])
A3 = sorted([A0[s] for s in A0])
A4 = [i for i in A1 if i in A3]
A5 = {i:i*i for i in A1}
A6 = [[i,i*i] for i in A1]
print(A0,A1,A2,A3,A4,A5,A6) |
Here’s the answer:
A0 = {‘a’: 1, ‘c’: 3, ‘b’: 2, ‘e’: 5, ‘d’: 4} # the order may vary
A1 = range(0, 10)
A2 = []
A3 = [1, 2, 3, 4, 5]
A4 = [1, 2, 3, 4, 5]
A5 = {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
A6 = [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36], [7, 49], [8, 64], [9, 81]]
167. In NumPy, how will you read CSV data into an array?
This may be accomplished by utilizing the genfromtxt() method with a comma as the delimiter.
168. What is GIL?
The term GIL stands for Global Interpreter Lock. This is a mutex that helps thread synchronization by preventing deadlocks by limiting access to Python objects. GIL assists with multitasking (and not parallel computing).
169. What is PIP?
PIP denotes Python Installer Package. It is used to install various Python modules. It’s a command-line utility that creates a unified interface for installing various Python modules. It searches the internet for the package and installs it into the working directory without requiring any user intervention.
170. Write a program that checks if all of the numbers in a sequence are unique.
def check_distinct(data_list):
if len(data_list) == len(set(data_list)):
return True
else:
return False;
print(check_distinct([1,6,5,8])) #Prints True
print(check_distinct([2,2,5,5,7,8])) #Prints False
171. What is an operator in Python?
An operator is a symbol that is applied to a set of values to produce a result. An operator manipulates operands. Numeric literals or variables that hold values are known as operands. Unary, binary, and ternary operators are all possible. The unary operator, which requires only one operand, the binary operator, which requires two operands, and the ternary operator, which requires three operands.
172. What are the various types of operators in Python?
- Bitwise operators
- Identity operators
- Membership operators
- Logical operators
- Assignment operators
- Relational operators
- Arithmetic operators
173. How to write a Unicode string in Python?
The old Unicode type has been replaced with the “str” type in Python 3, and the string is now considered Unicode by default. Using the art.title.encode(“utf-8”) function, we can create a Unicode string.
174. How to send an email in Python language?
Python includes the smtplib and email libraries for sending emails. Import these modules into the newly generated mail script and send mail to users who have been authenticated.
175. Create a program to add two integers >0 without using the plus operator.
def add_nums(num1, num2):
while num2 != 0:
data = num1 & num2
num1 = num1 ^ num2
num2 = data << 1
return num1
print(add_nums(2, 10))
176. Create a program to convert dates from yyyy-mm-dd to dd-mm-yyyyy.
We can use this module to convert dates:
import re
def transform_date_format(date):
return re.sub(r'(\d{4})-(\d{1,2})-(\d{1,2})’, ‘\\3-\\2-\\1’, date)
date_input = “2021-08-01”
print(transform_date_format(date_input))
The datetime module can also be used, as demonstrated below:
from datetime import datetime
new_date = datetime.strptime(“2021-08-01”, “%Y-%m-%d”).strftime(“%d:%m:%Y”)
print(new_data)
177. Create a program that combines two dictionaries. If you locate the same keys during combining, you can sum the values of these similar keys. Create a new dictionary.
from collections import Counter
d1 = {‘key1’: 50, ‘key2’: 100, ‘key3’:200}
d2 = {‘key1’: 200, ‘key2’: 100, ‘key4’:300}
new_dict = Counter(d1) + Counter(d2)
print(new_dict)
178. What kind of joins are offered by Pandas?
There are four joins in Pandas: left, inner, right, and outer.
179. How are dataframes in Pandas merged?
The type and fields of the dataframes being merged determine how they are merged. If the data has identical fields, it is combined along axis 0, otherwise, it is merged along axis 1.
180. What are generators and decorators in python?
Functions which return an iterable set of items are known as generators.
Generator functions act just like regular functions with just one difference they use the Python yield keyword instead of return.
A generator function is a function that returns an iterator. A generator expression is an expression that returns an iterator.
Generator objects are used either by calling the next method on the generator object or using the generator object in a “for in” loop.
A decorator in Python is any callable Python object that is used to modify a function or a class. It takes in a function, adds some functionality, and returns it.
Decorators are a very powerful and useful tool in Python since it allows programmers to modify/control the behaviour of a function or class.
Decorators are usually called before the definition of a function you want to decorate. There are two different kinds of decorators in Python:
Function decorators
Class decorators
181. Difference b/w numpy arrays and list
Arrays:
Arrays need to be imported using an array or numpy.
The collection of multiple items of the same data type in an array is another essential element.
Arrays need to have the same size as the array for nesting.
To print the array elements, a specific loop must be created.
An array consumes less memory in comparison to a list.
The array is not flexible because it makes it difficult to modify data.
We can apply direct arithmetic operations in an array.
Supports broadcasting, element-wise operations
Homogeneous (all elements of the same type)
Created using NumPy.array
Lists:
Lists are in-built data structures.
Lists collect items that typically have components of various data types.
In list variable size nesting is possible.
Without explicitly creating a loop, the List can be printed.
The List consumes more memory.
The List is ideal in terms of flexibility since it makes data modification simple.
In lists, it is not possible to apply arithmetic operations directly.
Does not support broadcasting efficiently
Heterogeneous (elements can have any type)
Created using square brackets [ ]