Machine Learning Models:
Top Supervised Machine Learning Algorithms
1. Linear Regression
A simple algorithm models a linear relationship between one or more explanatory variables and a continuous numerical output variable. It is faster to train as compared to other machine learning algorithms. Its biggest advantage lies in its ability to explain and interpret the model predictions. It is a regression algorithm used to predict outcomes like customer lifecycle value, housing prices, and stock prices.
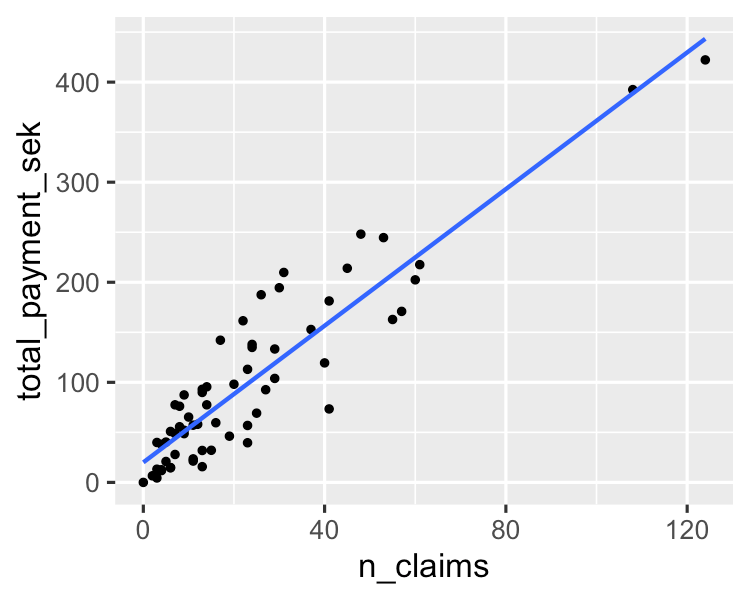
You can learn more about it in this essentials of linear regression in Python tutorial. If you are interested in getting hands-on with regression analysis, this much sought-after course on DataCamp is the right resource for you.
2. Decision Trees
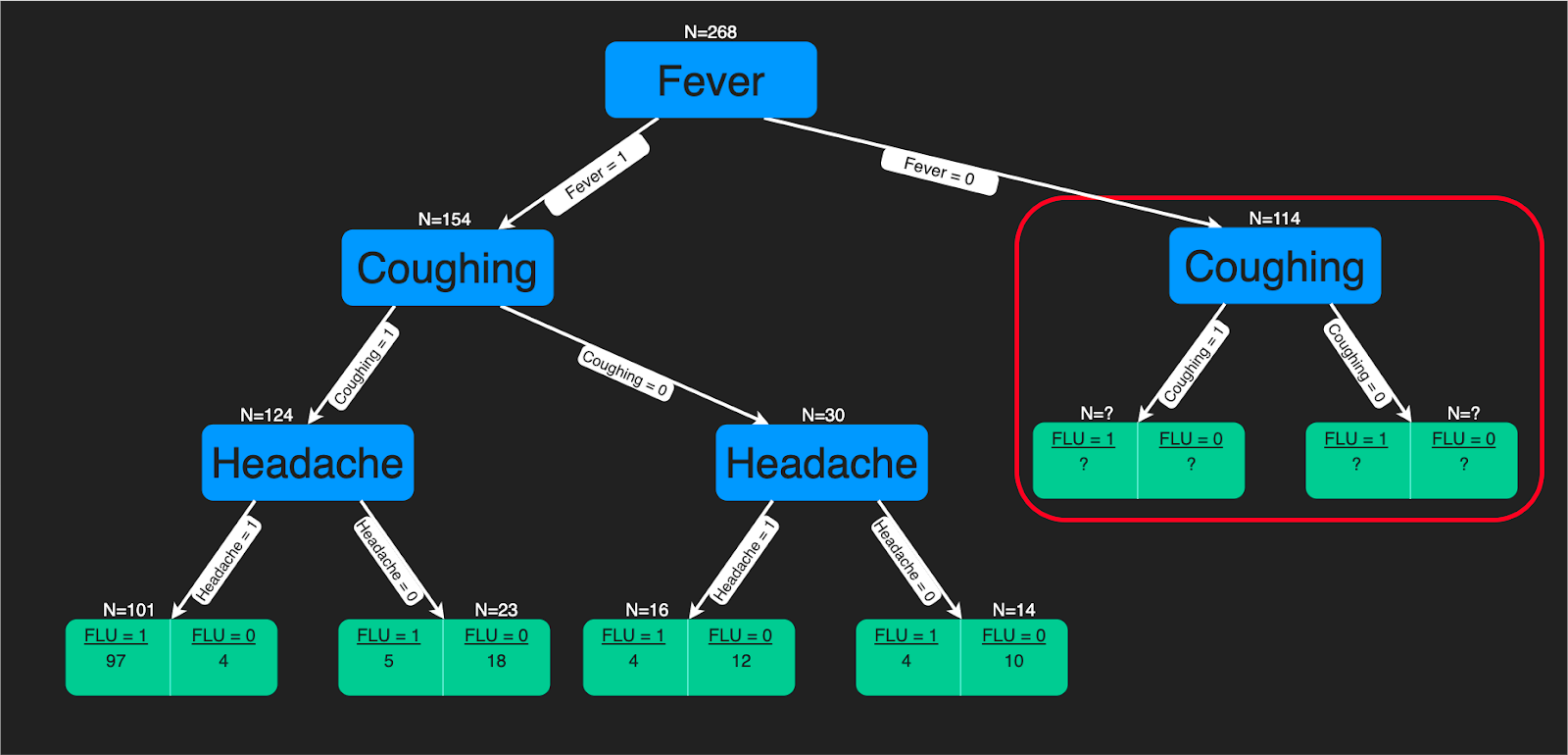
A decision tree algorithm is a tree-like structure of decision rules that are applied to the input features to predict the possible outcomes. It can be used for classification or regression. Decision tree predictions provide a good aid for healthcare experts as it is straightforward to interpret how those predictions are made.
You can refer to this tutorial if you are interested in learning how to build a decision tree classifier using Python. Further, if you are more comfortable using R, then you will benefit from this tutorial. There is also a comprehensive decision trees course on DataCamp.
3. Random Forest
It is arguably one of the most popular algorithms and builds upon the drawbacks of overfitting prominently seen in the decision tree models. Overfitting is when algorithms are trained on the training data a bit too well, and where they fail to generalize or provide accurate predictions on unseen data. Random forest solves the problem of overfitting by building multiple decision trees on randomly selected samples from the data. The final outcome in the form of the best prediction is derived from the majority voting of all the trees in the forest.
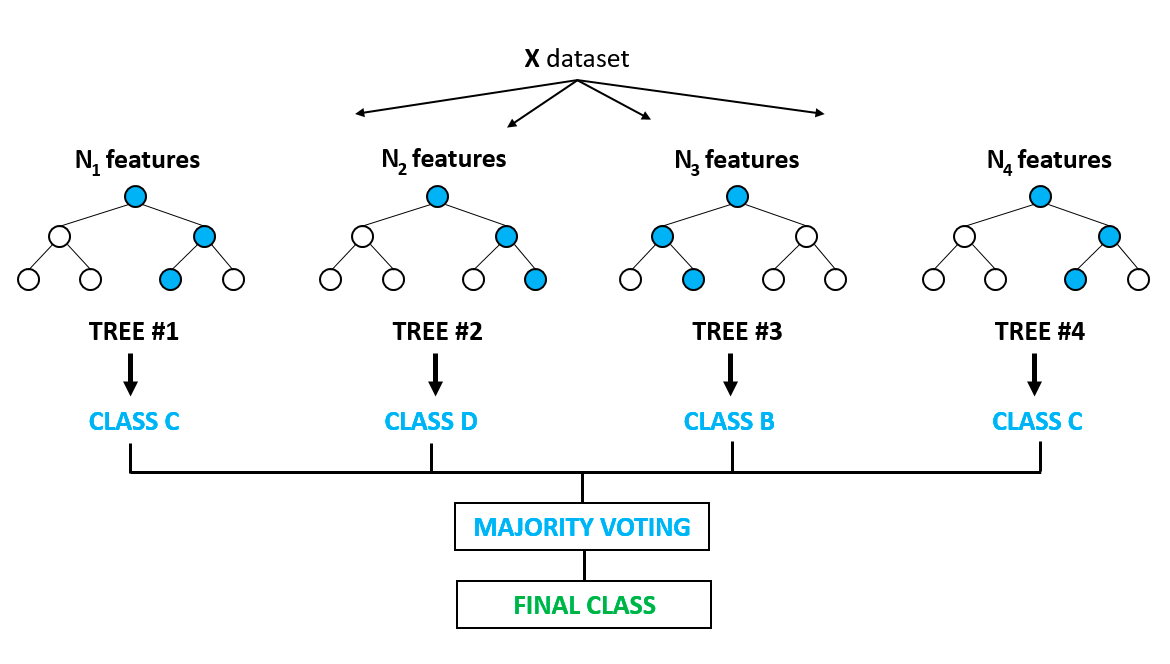
It is used for classification and regression problems both. It finds application in feature selection, disease detection, etc. You can learn more about tree-based models and ensembles (combining different individual models) from this very popular course on DataCamp. You can also learn more in this Python-based tutorial on implementing the random forest model.
4. Support Vector Machines
Support Vector Machines, commonly known as SVM, are generally used for classification problems. As shown in the example below, an SVM finds a hyperplane (line in this case), which segregates the two classes (red and green) and maximizes the margin (distance between the dotted lines) between them.
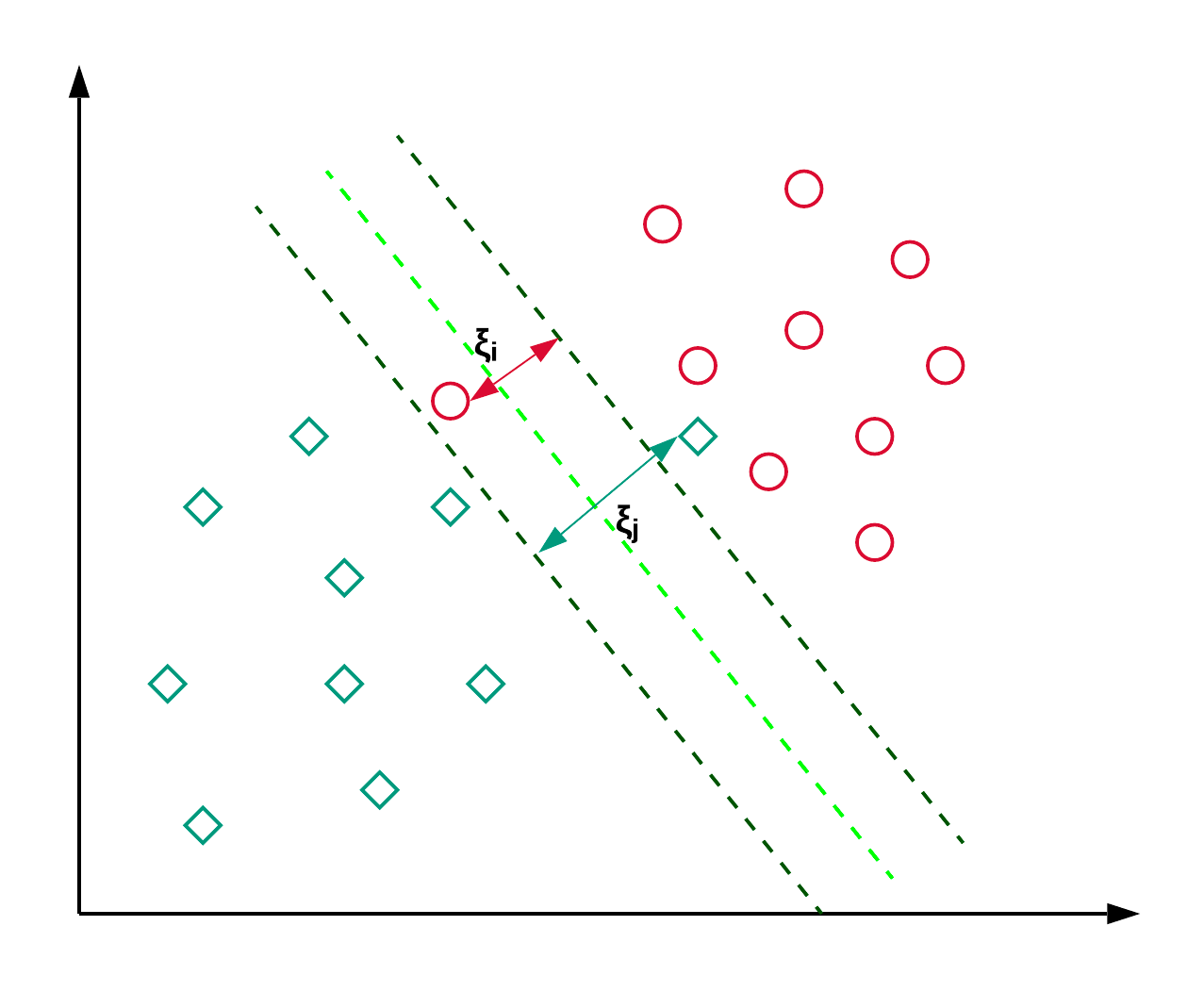
SVM is generally used for classification problems but can also be employed in regression problems. It is used to classify news articles and handwriting recognition. You can read more about the different types of kernel tricks along with the python implementation in this scikit-learn SVM tutorial. You can also follow this tutorial, where you’ll replicate the SVM implementation in R
5. Gradient Boosting Regressor
Gradient Boosting Regression is an ensemble model that combines several weak learners to make a robust predictive model. It is good at handling non-linearities in the data and multicollinearity issues.
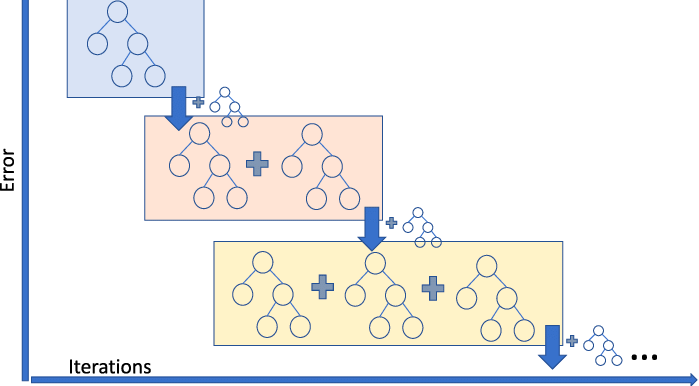
If you are in a ride sharing business and need to predict the ride fare amount, then you can use a gradient boosting regressor. If you want to understand the different flavors of gradient boosting, then you can watch this video on DataCamp.
Top Unsupervised Machine Learning Algorithms
6. K-means Clustering
K-Means is the most widely used clustering approach—it determines K clusters based on Euclidean distance. It is a very popular algorithm for customer segmentation and recommendation systems.
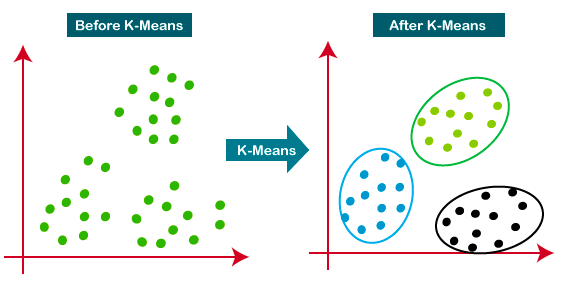
This tutorial is a great resource for learning more about K-means clustering.
7. Principal Component Analysis
Principal component analysis (PCA) is a statistical procedure that is used to summarize the information from a large data set by projecting it to a lower dimensional subspace. It is also called a dimensionality reduction technique that ensures retaining the essential parts of the data with higher information.
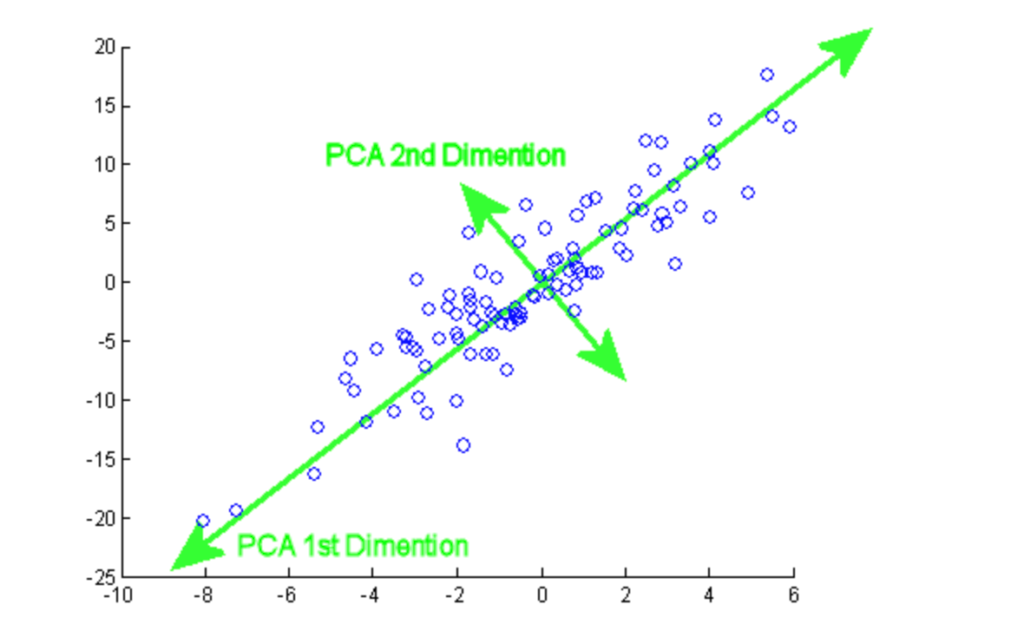
From this tutorial, you can practice hands-on PCA implementation on two popular datasets, Breast Cancer and CIFAR-10.
8. Hierarchical Clustering
It is a bottom-up approach where each data point is treated as its own cluster, and then the closest two clusters are merged together iteratively. Its biggest advantage over K-means clustering is that it does not require the user to specify the expected number of clusters at the onset. It finds application in document clustering based on similarity.
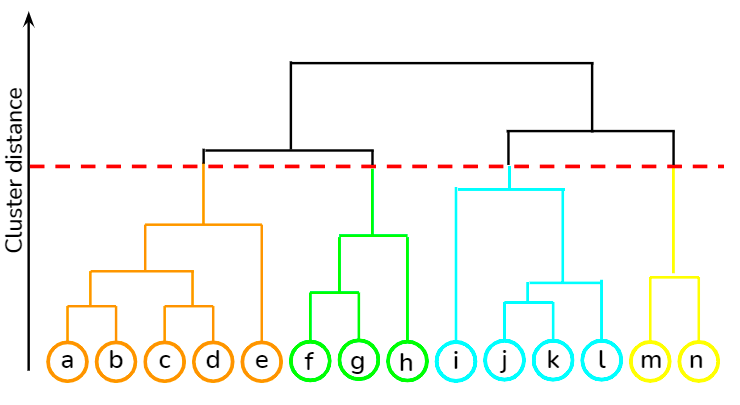
You can learn various unsupervised learning techniques, such as hierarchical clustering and K-means clustering, using the scipy library from this course at DataCamp. Besides, you can also learn how to apply clustering techniques to generate insights from unlabeled data using R from this course.
9. Gaussian Mixture Models
It is a probabilistic model for modeling normally distributed clusters within a dataset. It is different from the standard clustering algorithms in the sense that it estimates the probability of an observation belonging to a particular cluster and then dives into making inferences about its sub-population.
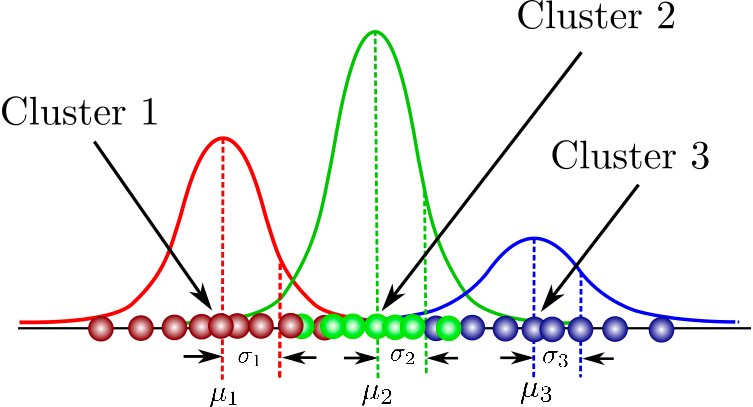
You can find a one-stop collation of courses here that covers fundamental concepts in model-based clustering, the structure of Mixture Models, and beyond. You will also get to practice hands-on gaussian mixture modeling using flexmix package.
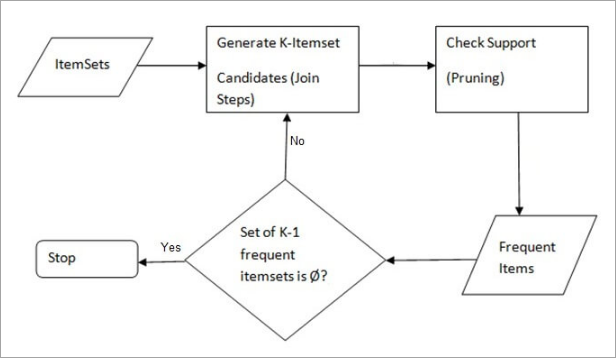
10. Apriori Algorithm
A rule-based approach that identifies the most frequent itemset in a given dataset where prior knowledge of frequent itemset properties is used. Market basket analysis employs this algorithm to help behemoths like Amazon and Netflix in translating the heaps of information about their users into simple rules of product recommendations. It analyses the associations between millions of products and uncovers insightful rules.
DataCamp provides a comprehensive course in both the languages—Python and R.
Classification Models:
Logistic Regression:
Regression Models:
Clustering Models:
Natural Language Processing Models:
Deep Learning Models: